


大数据是政府统计数据的重要补充来源,在政府统计中的应用越来越广泛。大数据的特点是数据来源丰富且数据类型多样,传统的数据采集方法难以应对,需要通过新技术来采集数据。网络数据抓取是获取大数据的重要技术之一。
一、什么是网络数据抓取
网络数据抓取(Web Scraping)是指采用技术手段从大量网页中提取结构化和非结构化信息,按照一定规则和筛选标准进行数据处理,并保存到结构化数据库中的过程。目前网络数据抓取采用的技术主要是对垂直搜索引擎(指针对某一个行业的专业搜索引擎)的网络爬虫(或数据采集机器人)、分词系统、任务与索引系统等技术的综合运用。
二、网络数据抓取有什么用
科学研究离不开翔实可靠的数据,互联网的发展提供了新的获取数据的手段。面对海量的互联网数据,网络数据抓取技术被视为一种行之有效的技术手段。相比于传统的数据采集方法,网络抓取数据无论时效性,还是灵活性均有一定的优势。利用网络数据抓取技术,可以在短时间内快速地抓取目标信息,构建大数据集以满足分析研究需要。
三、网络数据抓取流程
如图1所示,网络数据抓取的一般步骤包括:
(一)确定数据抓取的目标网站
根据研究需求确定所需信息的来源网站。
(二)网站的源代码分析
逐个分析各来源网站的数据信息组织形式,包括信息的展示方式以及返回方式,比如在线校验格式化的工具(JSON),在线格式化美化工具(XML)等,根据研究需求确定抓取字段。
(三)编写代码
分析时尽量找出各来源网站信息组织的共性,这样更便于编写服务器端和数据抓取端的代码。
(四)抓取环境测试
对抓取端进行代码测试,根据测试情况对代码进行修改和调整。
(五)数据抓取
将测试好的代码在目标网站进行正式数据抓取。
(六)数据存储
将抓取的数据以一定格式存储,比如将文本数据内容进行过滤和整理后,以excel、csv等格式存储,如果数据量较大也可以存储在关系型数据库(如MySQL,Oracle等),或非关系型数据库(如MongoDB)中来辅助随后的信息抽取和分析。若抓取积累的数据量大到一定程度,即达到大数据的级别,为了将来分析的效率性和方便性,可以将其直接存储于各类分布式大数据框架(如Hadoop和Spark等)提供的分布式文件系统中。数据存储完成后,基于整理好格式的数据,可以根据分析目标执行各类数据挖掘和机器学习算法,如分类、建模、预测等。
(七)应注意事项
根据《中华人民共和国网络安全法》,任何个人和组织不得从事非法侵入他人网络、窃取网络数据等危害网络安全的活动;不得窃取或者以其他非法方式获取个人信息。网络数据抓取行为应严格遵守法律和道德规范,通过合法合规方式来获取数据。
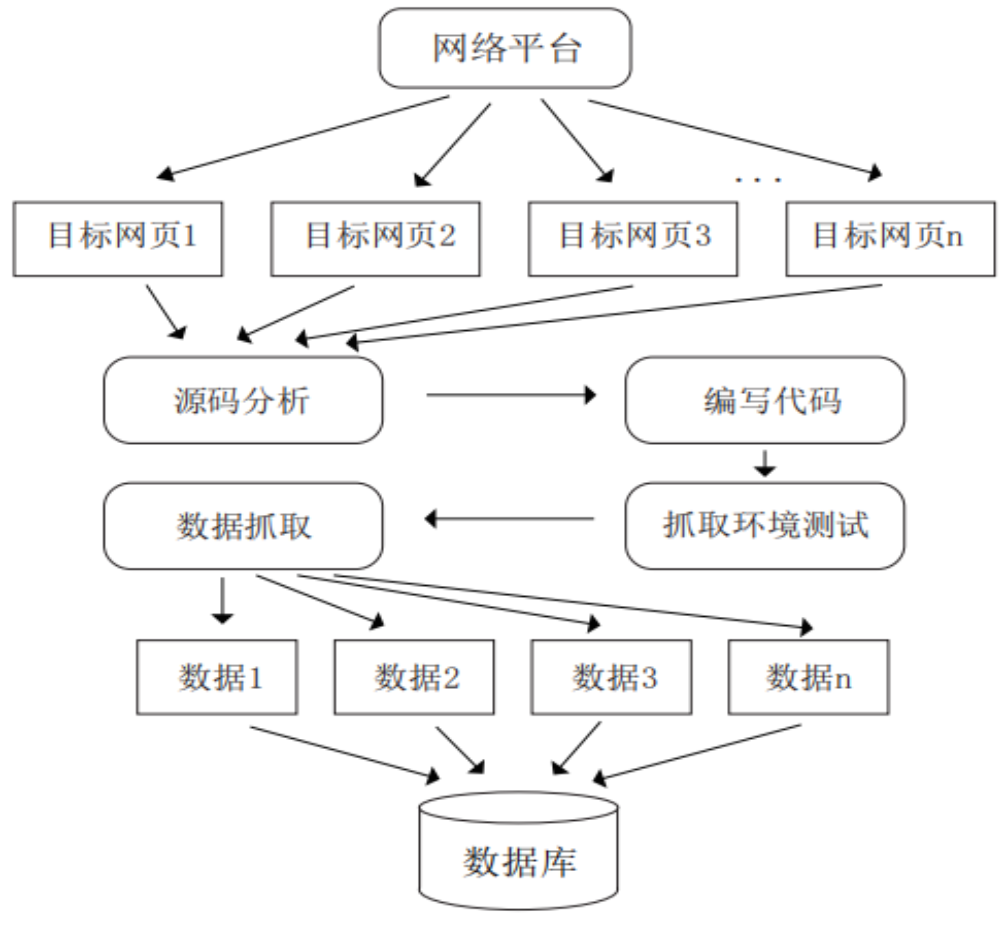
图1 网络数据抓取流程示意图
四、应用案例
目前基于网络抓取数据开展分析研究的实践非常普遍,美国Scott R.Baker等三位学者编制的经济政策不确定性(EPU)指数就是一个较为典型的案例。该指数当前已编制并发布全球以及多个国家和地区的测算结果,并得到较为广泛的认可和应用。以美国EPU指数为例(见图2),该指数的新闻分指数是基于全美销量排名前十的报纸,抓取含有“经济”“政策”“不确定性”等关键词在报纸上出现的文章数量,进行统计和标准化处理后建立的。
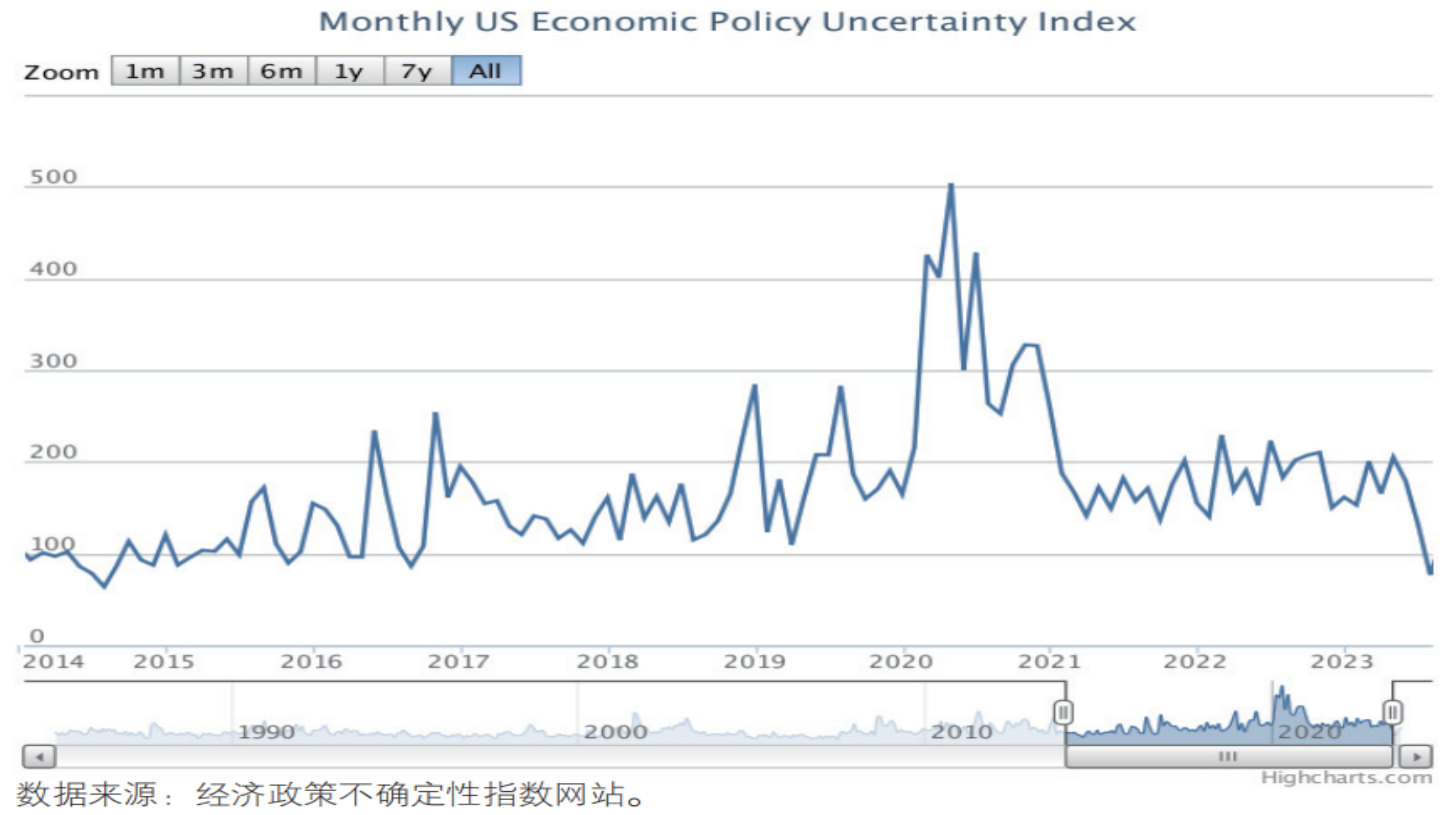
图2 2014年1月—2023年7月美国经济政策不确定性指数趋势图
