


一、规模以下工业抽样调查介绍
“四下”单位抽样调查统计报表制度是为反映规模(限额)以下企业、产业活动单位和个体经营户的基本情况、生产经营状况、固定资产投资、创新、研发等发展情况而设计的。调查范围涵盖规模以下工业、资质外建筑业、限额以下批发和零售业、限额以下住宿和餐饮业、规模以下服务业四类。其中,规模以下工业作为“四下”单位抽样调查的重要组成部分,对反映“四下”工业单位情况,起到不可或缺的作用。
(一)基本抽样方法
企业子总体中有企业名录的部分采用一阶段分层随机抽样,没有企业名录的企业和个体工业子总体采用分层随机整群抽样方法。对于目录企业部分,根据各省(区、市)企业名录库直接抽取样本企业;对于个体经营工业单位和未包括在企业名录库中的非目录企业部分,在省一级直接抽取整群单位——村(居委会)作为样本,对整群样本内部的个体工业单位和非目录企业全部调查。
(二)抽样精度
在95%的置信度下,最大相对误差控制在10%以内。
(三)调查目标
一是估计全国和各省规模以下工业总体、企业子总体和个体工业子总体的指标总量。二是估计全国企业子总体分行业大类的指标总量。
二、规模以下工业抽样调查设计
(一)目录企业抽样设计
1.整理抽样框
目录企业抽样框的范围包括全部有名录的规模以下工业企业。抽样框内容应包括企业的基本属性指标和基本价值量指标。具体包括:企业名称、地址、行业分类、企业登记注册类型等基本属性指标,以及营业收入等基本价值量指标。
2.确定样本量
为了同时满足企业子总体以省为总体抽样精度的要求和以全国分行业大类为总体抽样精度的要求,由国家统计局工业司分别确定各省目录企业部分的样本量和样本的行业分布结构。
3.分层及样本量在各层之间的分配
(1)按行业大类分层
先将目录企业抽样框按照行业大类分成41个行业层,将已确定的样本量分配到各行业层中,若出现某些行业层没有分配到样本,则在该层增加2到4个样本量。
(2)行业层内部进一步分层
在完成按行业大类分层之后,如果分配给某行业层的样本量较大时,则需要在行业层内部进一步分层,以提高估计量的精度。进一步分层的限制条件是,每个最终层内包含4个以上样本量。
4.抽取样本
采用“永久随机数”方法抽取样本。首先对抽样框中的每个单位赋予一个“永久随机数”,然后在每一个最终层中将企业按照“永久随机数”从小到大排队,抽取![]() 个最小永久随机数的企业作为第
个最小永久随机数的企业作为第![]() 层的样本。
层的样本。
5.确定权数
(1)基础权数
目录企业样本的基础权数是该样本企业被选概率的倒数。
(2)最终权数
根据检查是否存在无回答有效样本企业等情况对相应样本企业的基础权数进行调整,得到每个样本企业的最终权数。
6.总量估计
(1)总量估计量

其中,![]() 为样本企业
为样本企业![]() 的最终权数,
的最终权数,![]() 为样本企业
为样本企业![]() 的指标
的指标![]() 的值。
的值。
(2)子域总量估计量
![]()
其中,![]() 为要研究的子域(如行业等),
为要研究的子域(如行业等),![]() 为样本企业
为样本企业![]() 的最终权数,
的最终权数,![]() 为样本企业
为样本企业![]() 的指标
的指标![]() 的值。
的值。
(二)个体工业抽样设计
1.整理抽样框
个体工业一阶段整群抽样框,包括全省(自治区、直辖市)范围内所有的村(居委会),既包括有个体工业单位的村(居委会),也包括没有个体工业单位的村(居委会)。抽样框的内容包括:村(居委会)名称、区划代码、村内个体工业单位数和营业收入等信息,对于没有个体工业单位的村(居委会)来说,个体工业单位数和营业收入为“0”。
2.确定样本量
根据精度要求,计算样本量。
3.分层及样本量在各层之间的分配
将村(居委会)按照规模分层。可灵活掌握分层数量,采用累计平方根法确定分层界限。按照规模较大层采取较大抽样比的原则,进行样本分配。
4.抽取样本
采用“永久随机数”方法抽取样本。首先对抽样框中每个单位赋予一个随机数,然后在每一个最终层中将村(居委会)按照随机数大小排队,抽取![]() 个最小永久随机数的村(居委会)作为第
个最小永久随机数的村(居委会)作为第![]() 层的样本。
层的样本。
5.确定权数
(1)基础权数
样本村(居委会)的基础权数是该样本村(居委会)的被选概率的倒数,个体工业单位的基础权数等于其所在村(居委会)的基础权数。
(2)最终权数
根据检查是否存在无回答样本村(居委会)、是否存在无回答个体工业单位等情况,对相应个体工业单位的基数权数进行调整,得到每个个体工业单位的最终权数。
6.总量估计
![]()
其中,![]() 为个体工业单位
为个体工业单位![]() 的最终权数,
的最终权数,![]() 为个体工业单位
为个体工业单位![]() 的指标
的指标![]() 的值。
的值。
(三)非目录企业抽样设计
1.抽样方法
对非目录企业采用一阶段整群抽样方法。利用个体工业一阶段整群抽样的样本,对样本村(居委会)范围内的规模以下工业企业进行核查,确认非目录企业样本。
2.确定非目录企业样本
首次使用《非目录企业核查表》时,由各省级统计局提供样本村(居委会)范围内的“目录企业”名单给样本村(居委会)调查员。样本村(居委会)调查员,对比本村(居委会)所有规模以下工业企业,找出本村(居委会)“目录企业”名单之外的、在本村(居委会)范围内的规模以下工业企业,并把这部分企业名单填在《非目录企业核查表》中的“非目录企业”栏内。
在同一目录企业抽样框条件下,第二次及以后执行《非目录企业核查表》采用累计核对法,即各省级统计局提供给样本村(居委会)调查员的企业名单包括“目录企业”和本次调查之前核对出来的所有“非目录企业”两部分,样本村(居委会)调查员根据这两部分企业名单,开展本次核对并填报《非目录企业核查表》。
将村(居委会)调查员填报的“非目录企业”名单与目录企业抽样框内的企业再次进行核对,从“非目录企业”名单中,剔除目录企业抽样框中已经存在的重复企业,剩下的“非目录企业”,最终作为非目录企业样本。
3.确定权数
(1)基础权数
非目录企业的基础权数等于所在样本村(居委会)的基础权数。
(2)最终权数
根据检查是否存在无回答样本村(居委会)、是否存在无回答非目录企业等情况,对相应非目录企业样本的基础权数进行调整,得到每个非目录企业样本的最终权数。
4.总量估计
![]()
其中,![]() 为非目录企业
为非目录企业![]() 的最终权数,
的最终权数,![]() 为非目录企业
为非目录企业![]() 的指标
的指标![]() 的值。
的值。
(四)总体总量和方差估计
1.企业子总体总量和方差估计
(1)总量估计量
![]()
其中,![]() 表示目录企业的总量估计量,
表示目录企业的总量估计量,![]() 表示非目录企业的总量估计量。
表示非目录企业的总量估计量。
(2)方差估计量
![]()
2.规模以下工业总体总量和方差估计
(1)总量估计量
![]()
其中,![]() 表示企业子总体的总量估计量,
表示企业子总体的总量估计量,![]() 表示个体工业子总体的总量估计量,
表示个体工业子总体的总量估计量,![]() 表示目录企业的总量估计量,
表示目录企业的总量估计量,![]() 表示非目录企业的总量估计量。
表示非目录企业的总量估计量。
(2)方差估计量
在估计规模以下工业总体总量的方差时,由于非目录企业和个体工业单位的样本是来源于同一个整群样本,因此需要将非目录企业和个体工业单位作为一个整体,用一阶段整群抽样的方差估计量公式,估计非目录企业和个体工业单位![]() 的方差,则
的方差,则![]() 的方差估计量为:
的方差估计量为:![]()
(3)最大相对误差估计量
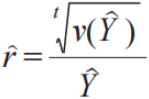
其中,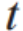 =1.96。
=1.96。
